10.3. timelineId and Timeline History File
A timeline in PostgreSQL is used to distinguish between the original database cluster and the recovered ones. It is a central concept of PITR. In this section, two things associated with the timeline are described: timelineId and timeline history files.
10.3.1. timelineId
Each timeline is given a corresponding timelineId, a 4-byte unsigned integer starting at 1.
An individual timelineId is assigned to each database cluster. The timelineId of the original database cluster created by the initdb utility is 1. Whenever a database cluster recovers, the timelineId is increased by 1. For example, in the example of the previous section, the timelineId of the cluster recovered from the original one is 2.
Figure 10.4 illustrates the PITR process from the viewpoint of the timelineId.
First, we remove our current database cluster and restore the base backup made in the past, in order to go back to the starting point of recovery. This situation is represented by the red arrow curve in the figure.
Next, we start the PostgreSQL server, which replays WAL data in the archive logs from the REDO point created by the pg_backup_start until the recovery target by tracing along the initial timeline (timelineId 1). This situation is represented by the blue arrow line in the figure. Then, a new timelineId 2 is assigned to the recovered database cluster and PostgreSQL runs on the new timeline.
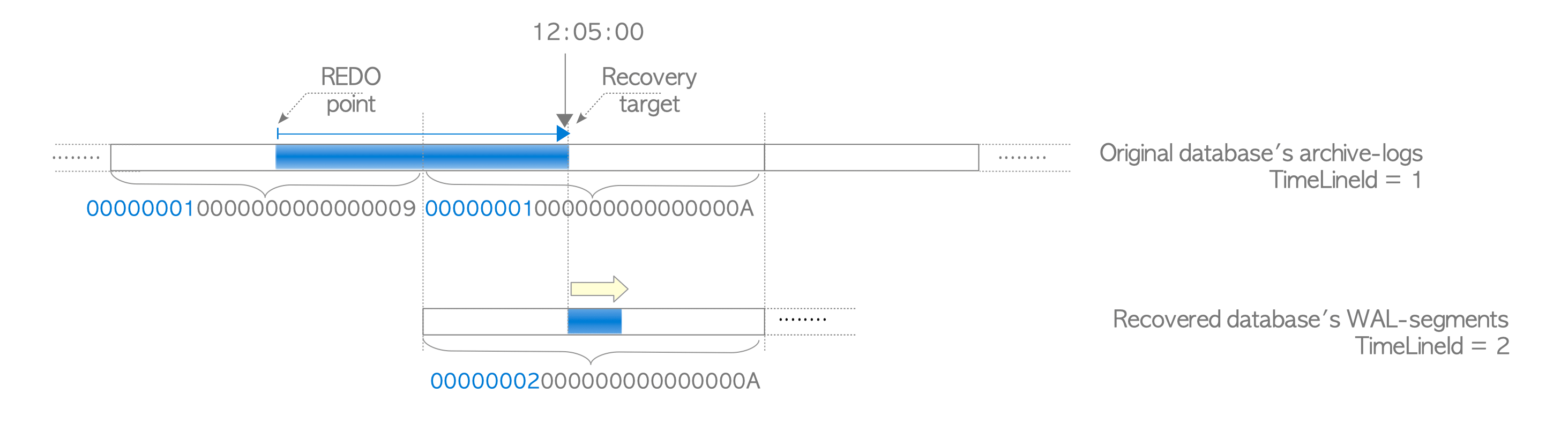
Figure 10.4. Relation of timelineId between an original and a recovered database clusters.
As briefly mentioned in Chapter 9, the first 8 digits of the WAL segment filename are equal to the timelineId of the database cluster that created the segment. When the timelineId is changed, the WAL segment filename will also be changed.
Focusing on WAL segment files, the recovery process can be described again. Suppose that we recover the database cluster using two archive logs ‘000000010000000000000009’ and ‘00000001000000000000000A’. The newly recovered database cluster is assigned the timelineId 2, and PostgreSQL creates the WAL segment from ‘00000002000000000000000A’.
Figure 10.5 shows this situation.
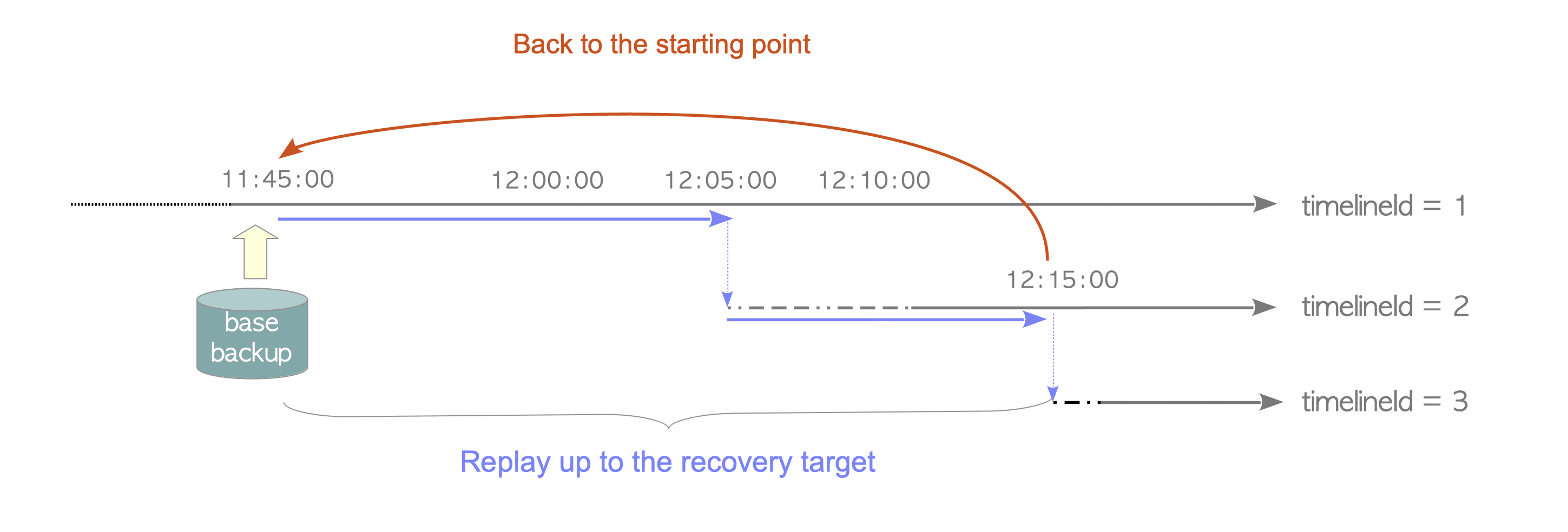
Figure 10.5. Relation of WAL segment files between an original and a recovered database clusters.
10.3.2. Timeline History File
When a PITR process completes, a timeline history file with names like ‘00000002.history’ is created under the archival directory and the pg_xlog subdirectory (in versions 10 or later, pg_wal subdirectory). This file records which timeline it branched off from and when.
The naming rule of this file is shown below:
"8-digit new timelineId".historyThe timeline history file contains at least one line, and each line is composed of the following three items:
- timelineId – The timelineId of the archive logs used to recover.
- LSN – The LSN location where the WAL segment switches happened.
- reason – A human-readable explanation of why the timeline was changed.
A specific example is shown below:
$ cat /home/postgres/archivelogs/00000002.history
1 0/A000198 before 2024-1-1 12:05:00.861324+00Meaning as follows:
The database cluster (timelineId = 2) is based on the base backup whose timelineId is 1, and is recovered in the time just before ‘2024-1-1 12:05:00.861324+00’ by replaying the archive logs until the ‘0/A000198’.
In this way, each timeline history file tells us a complete history of the individual recovered database cluster. Moreover, it is also used in the PITR process itself. The details are explained in the next section.
The timeline history file format is changed in version 9.3. The formats of versions 9.3 or later and earlier are shown below, but not in detail.
Later version 9.3:
timelineId LSN "reason"Until version 9.2:
timelineId WAL_segment "reason"