5.9. Serializable Snapshot Isolation
Serializable Snapshot Isolation (SSI) has been embedded in SI since version 9.1 to realize a true SERIALIZABLE isolation level. Since the explanation of SSI is not simple, only an outline is explained. For details, see the original paper : “Serializable Snapshot Isolation in PostgreSQL”
In the following, the technical terms shown in below are used without definitions.
-
precedence graph (also known as dependency graph and serialization graph)
-
serialization anomalies (e.g. Write-Skew)
If you are unfamiliar with these terms, see the references:
-
Abraham Silberschatz, Henry F. Korth, and S. Sudarshan, “Database System Concepts”, McGraw-Hill Education, ISBN-13: 978-0073523323
-
Thomas M. Connolly, and Carolyn E. Begg, “Database Systems”, Pearson, ISBN-13: 978-0321523068
5.9.1. Basic Strategy for SSI Implementation
If a cycle is present in the precedence graph, there will be a serialization anomaly. This can be explained using the simplest anomaly, write-skew.
Figure 5.12(1) shows a schedule. Here, Transaction_A reads Tuple_B and Transaction_B reads Tuple_A. Then, Transaction_A writes Tuple_A and Transaction_B writes Tuple_B. In this case, there are two rw-conflicts, and they make a cycle in the precedence graph of this schedule, as shown in Figure 5.12(2). Thus, this schedule has a serialization anomaly, Write-Skew.
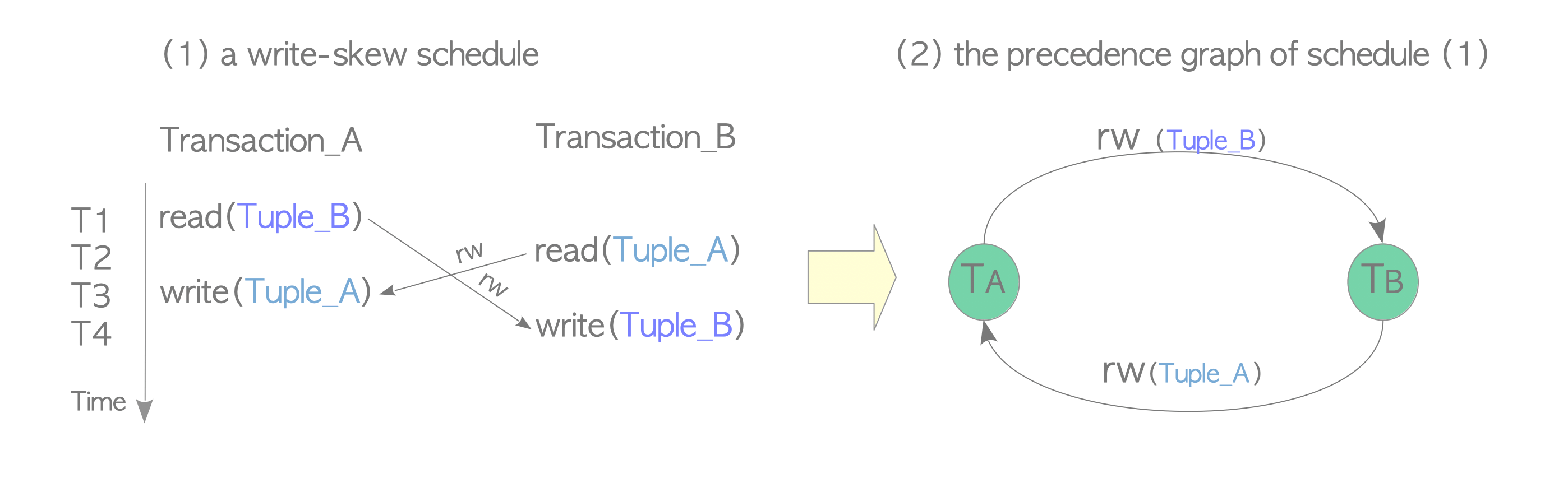
Figure 5.12. Write-Skew schedule and its precedence graph.
Conceptually, there are three types of conflicts: wr-conflicts (Dirty Reads), ww-conflicts (Lost Updates), and rw-conflicts. However, wr- and ww-conflicts do not need to be considered because PostgreSQL prevents such conflicts, as shown in the previous sections. Thus, SSI implementation in PostgreSQL only needs to consider rw-conflicts.
PostgreSQL takes the following strategy for the SSI implementation:
- Record all objects (tuples, pages, relations) accessed by transactions as SIREAD locks.
- Detect rw-conflicts using SIREAD locks whenever any heap or index tuple is written.
- Abort the transaction if a serialization anomaly is detected by checking detected rw-conflicts.
5.9.2. Implementing SSI in PostgreSQL
To realize the strategy described above, PostgreSQL has implemented many functions and data structures. However, here we uses only two data structures: SIREAD locks and rw-conflicts, to describe the SSI mechanism. They are stored in shared memory.
For simplicity, some important data structures, such as SERIALIZABLEXACT, are omitted in this document. Thus, the explanations of the functions, i.e. CheckForSerializableConflictOut, CheckForSerializableConflictIn, and PreCommit_CheckForSerializationFailure, are also extremely simplified.
For example, we indicate which functions detect conflicts; however, how the conflicts are detected is not explained in detail.
For detailed information, refer to the source code: src/backend/storage/lmgr/predicate.c.
- SIREAD locks:
An SIREAD lock, internally called a predicate lock, is a pair of an object and (virtual) txids that store information about who has accessed which object.
Note that the description of virtual txid is omitted. The term txid is used rather than virtual txid to simplify the following explanation.
SIREAD locks are created by the CheckForSerializableConflictOut function whenever a DML command is executed in SERIALIZABLE mode. For example, if txid 100 reads Tuple_1 of the given table, an SIREAD lock {Tuple_1, {100}} is created. If another transaction, e.g. txid 101, reads Tuple_1, the SIREAD lock is updated to {Tuple_1, {100,101}}.
Note that a SIREAD lock is also created when an index page is read because an index page is only read without reading the table page when the Index-Only Scans feature, which is described in Section 7.2, is applied.
SIREAD lock has three levels: tuple, page, and relation.
If the SIREAD locks of all tuples within a single page are created, they are aggregated into a single SIREAD lock for that page, and all SIREAD locks of the associated tuples are released (removed), to reduce memory space.
The same is true for all pages that are read.
When using sequential scan, a relation level SIREAD lock is created from the beginning regardless of the presence of indexes and/or WHERE clauses. Note that, in certain situations, this implementation can cause false-positive detections of serialization anomalies. The details are described in Section 5.9.4.
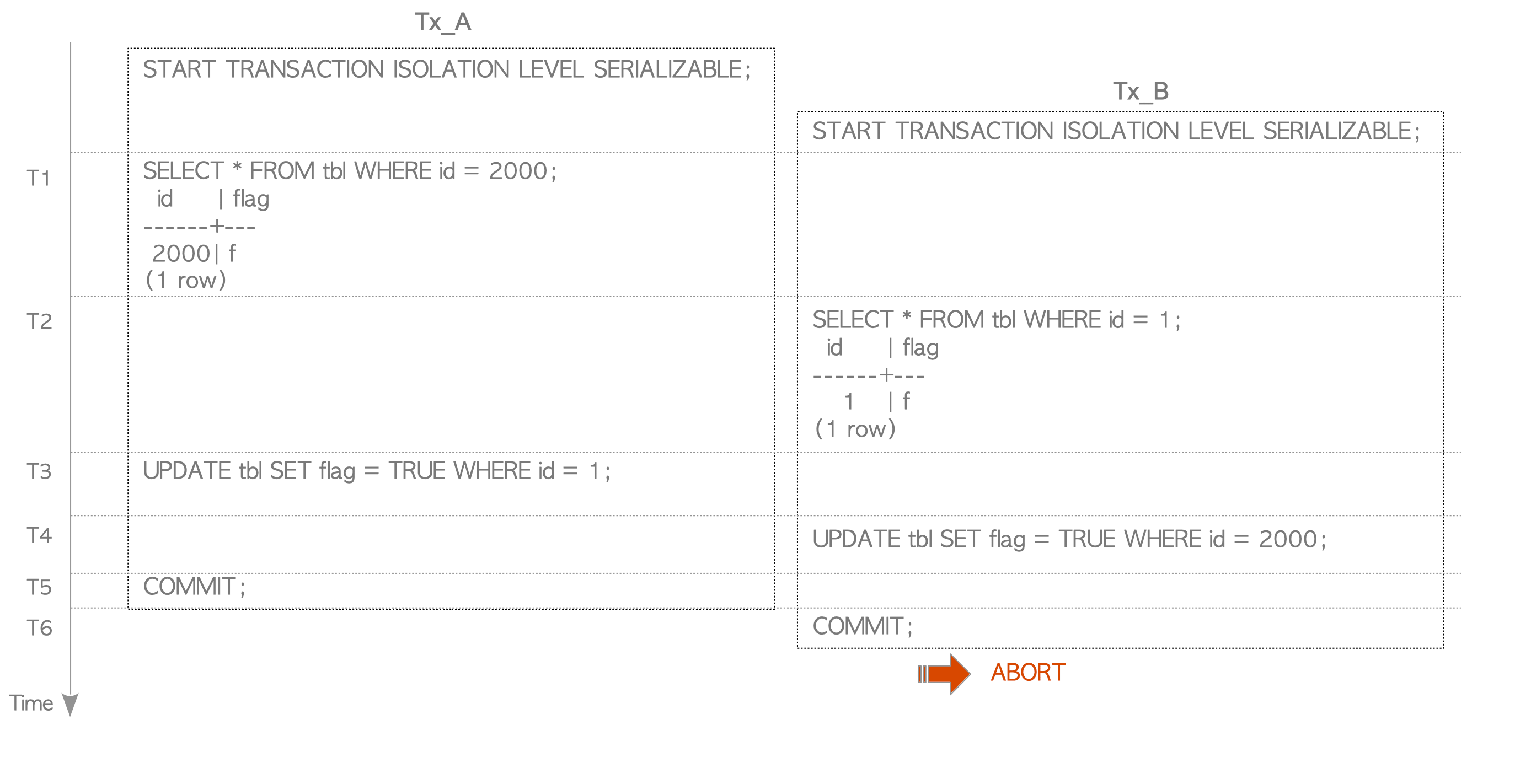
Figure 5.13. Example of SIREAD Lock Aggregation.
Assume that a transaction Tx has read tuple_1 and tuple_2 in Page_1. In this case, two tuple-level SIREAD locks are created. Next, Tx reads tuple_3, meaning all tuples in Page_1 have now been read. At this point, the tuple-level SIREAD locks on Page_1 are removed and created with a page-level SIREAD lock.
- rw-conflicts:
A rw-conflict is a triplet of an SIREAD lock and two txids that reads and writes the SIREAD lock.
The CheckForSerializableConflictIn function is invoked whenever either an INSERT, UPDATE, or DELETE command is executed in SERIALIZABLE mode, and it creates rw-conflicts when detecting conflicts by checking SIREAD locks.
For example, assume that txid 100 reads Tuple_1 and then txid 101 updates Tuple_1. In this case, the CheckForSerializableConflictIn function, invoked by the UPDATE command in txid 101, detects a rw-conflict with Tuple_1 between txid 100 and 101 and then creates a rw-conflict {r=100, w=101, {Tuple_1}}.
Both the CheckForSerializableConflictOut and CheckForSerializableConflictIn functions, as well as the PreCommit_CheckForSerializationFailure function, which is invoked when the COMMIT command is executed in SERIALIZABLE mode, check serialization anomalies using the created rw-conflicts. If they detect anomalies, only the first-committed transaction is committed and the other transactions are aborted (by the first-committer-win scheme).
5.9.3. How SSI Performs
Here, we describe how SSI resolves Write-Skew anomalies. We use a simple table ’tbl’ shown below:
testdb=# CREATE TABLE tbl (id INT primary key, flag bool DEFAULT false);
testdb=# INSERT INTO tbl (id) SELECT generate_series(1,2000);
testdb=# ANALYZE tbl;Transactions Tx_A and Tx_B execute the following commands (Figure 5.14).
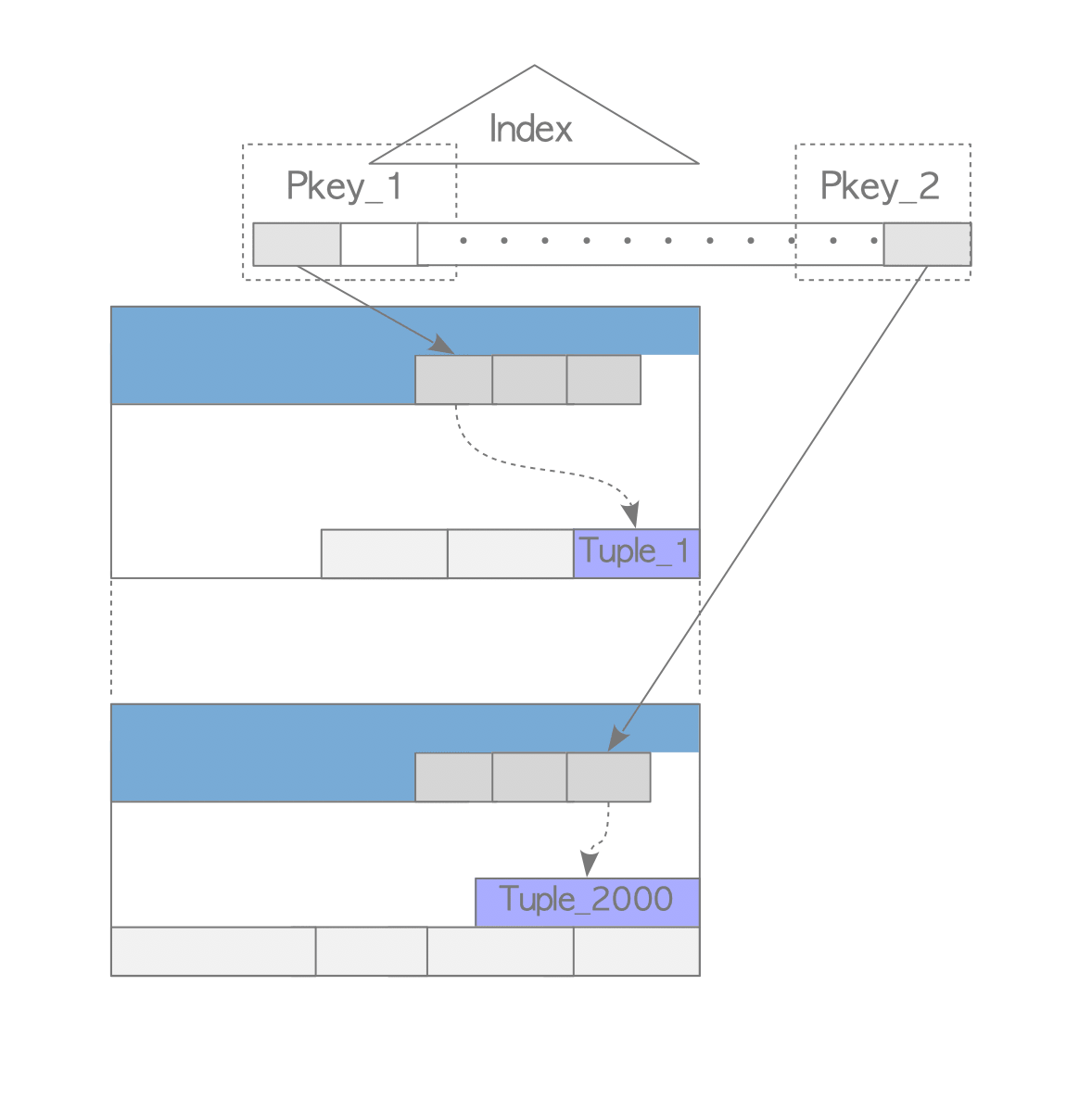
Figure 5.14. Write-Skew scenario.
Assume that all commands use index scan. Therefore, when the commands are executed, they read both heap tuples and index pages, each of which contains the index tuple that points to the corresponding heap tuple. See Figure 5.15.
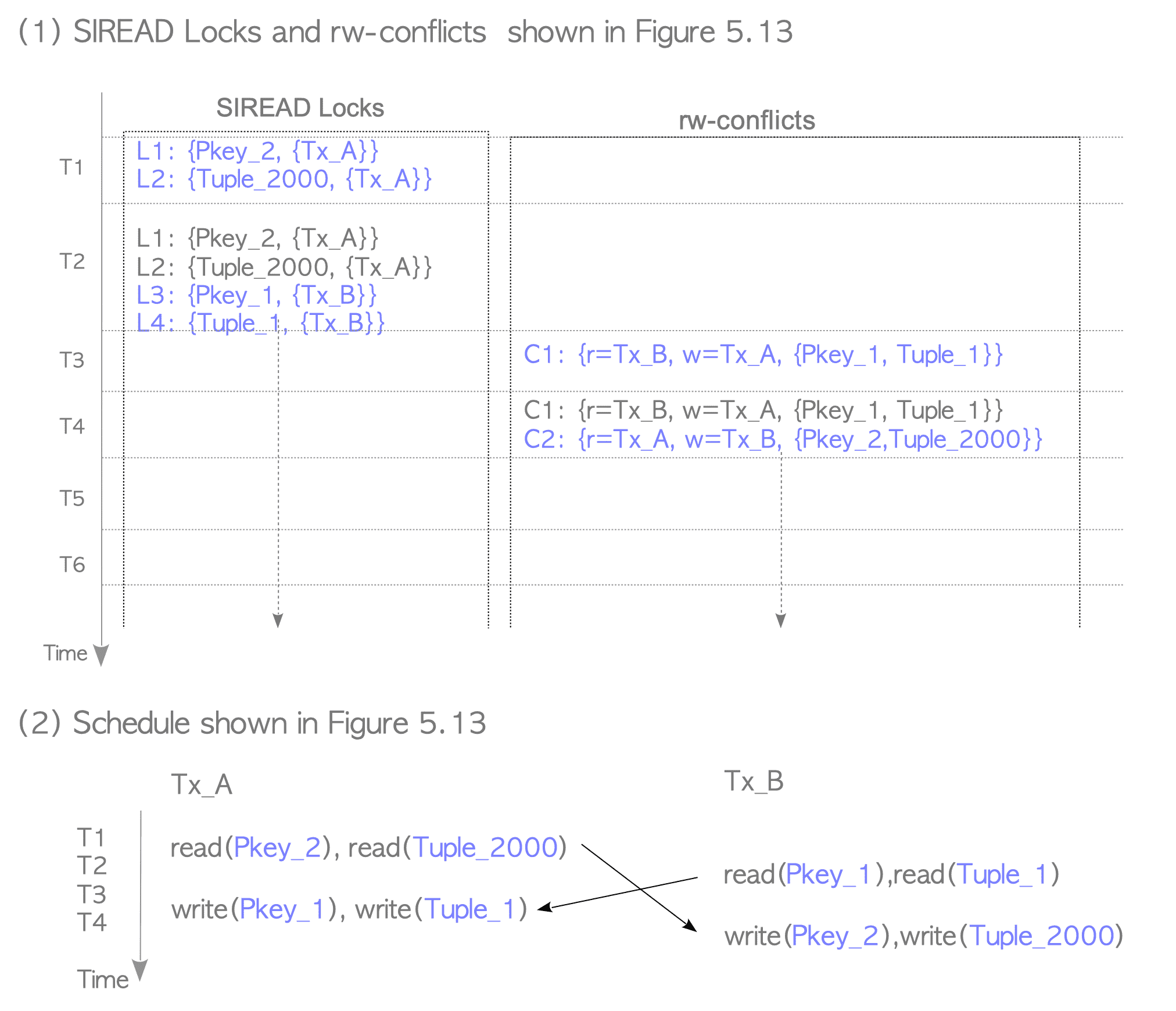
Figure 5.15. Relationship between the index and table in the scenario shown in Figure 5.14.
-
T1: Tx_A executes a SELECT command. This command reads a heap tuple (Tuple_2000) and one page of the primary key (Pkey_2).
-
T2: Tx_B executes a SELECT command. This command reads a heap tuple (Tuple_1) and one page of the primary key (Pkey_1).
-
T3: Tx_A executes an UPDATE command to update Tuple_1.
-
T4: Tx_B executes an UPDATE command to update Tuple_2000.
-
T5: Tx_A commits.
-
T6: Tx_B commits; however, it is aborted due to a Write-Skew anomaly.
Figure 5.16 shows how PostgreSQL detects and resolves the Write-Skew anomaly described in the above scenario.
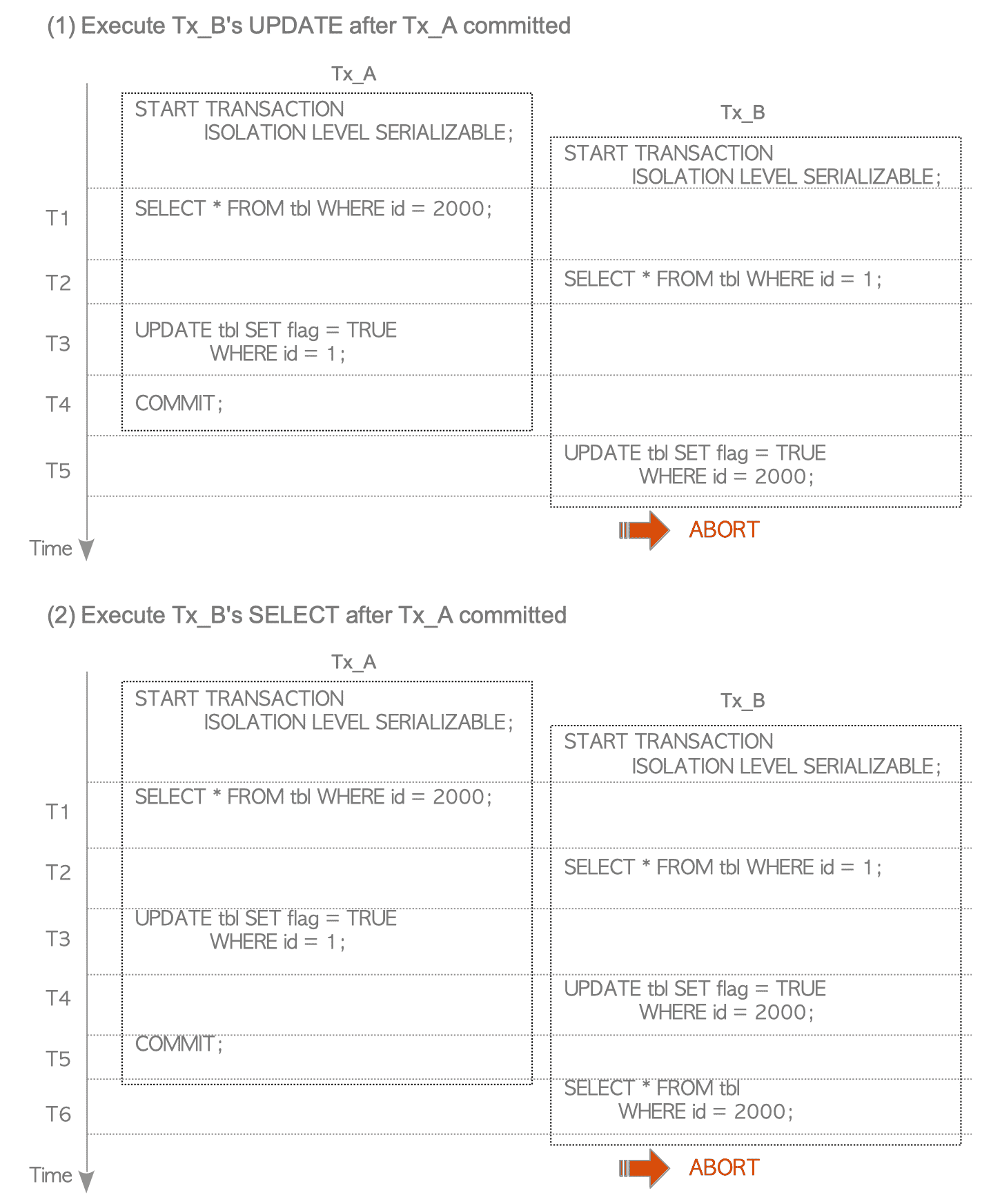
Figure 5.16. SIREAD locks and rw-conflicts, and schedule of the scenario shown in Figure 5.14.
-
T1:
When executing the SELECT command of Tx_A, CheckForSerializableConflictOut creates SIREAD locks. In this scenario, the function creates two SIREAD locks: L1 and L2.
L1 and L2 are associated with Pkey_2 and Tuple_2000, respectively. -
T2:
When executing the SELECT command of Tx_B, CheckForSerializableConflictOut creates two SIREAD locks: L3 and L4.
L3 and L4 are associated with Pkey_1 and Tuple_1, respectively. -
T3:
When executing the UPDATE command of Tx_A, both CheckForSerializableConflictOut and CheckTargetForConflictsIN are invoked before and after ExecUpdate.
In this scenario, CheckForSerializableConflictOut does nothing.
CheckForSerializableConflictIn creates rw-conflict C1, which is the conflict of both Pkey_1 and Tuple_1 between Tx_B and Tx_A, because both Pkey_1 and Tuple_1 were read by Tx_B and written by Tx_A. -
T4:
When executing the UPDATE command of Tx_B, CheckForSerializableConflictIn creates rw-conflict C2, which is the conflict of both Pkey_2 and Tuple_2000 between Tx_A and Tx_B.
In this scenario, C1 and C2 create a cycle in the precedence graph; thus, Tx_A and Tx_B are in a non-serializable state. However, both transactions Tx_A and Tx_B have not been committed, therefore CheckForSerializableConflictIn does not abort Tx_B. Note that this occurs because PostgreSQL’s SSI implementation is based on the first-committer-win scheme. -
T5:
When Tx_A attempts to commit, PreCommit_CheckForSerializationFailure is invoked. This function can detect serialization anomalies and can execute a commit action if possible. In this scenario, Tx_A is committed because Tx_B is still in progress. -
T6:
When Tx_B attempts to commit, PreCommit_CheckForSerializationFailure detects a serialization anomaly and Tx_A has already been committed; thus, Tx_B is aborted.
5.9.3.1. Other Scenarios
In addition, if the UPDATE command is executed by Tx_B after Tx_A has been committed (at T5), Tx_B is immediately aborted because CheckForSerializableConflictIn invoked by Tx_B’s UPDATE command detects a serialization anomaly (Figure 5.17(1)).
If the SELECT command is executed instead of COMMIT at T6, Tx_B is immediately aborted because CheckForSerializableConflictOut invoked by Tx_B’s SELECT command detects a serialization anomaly (Figure 5.17(2)).
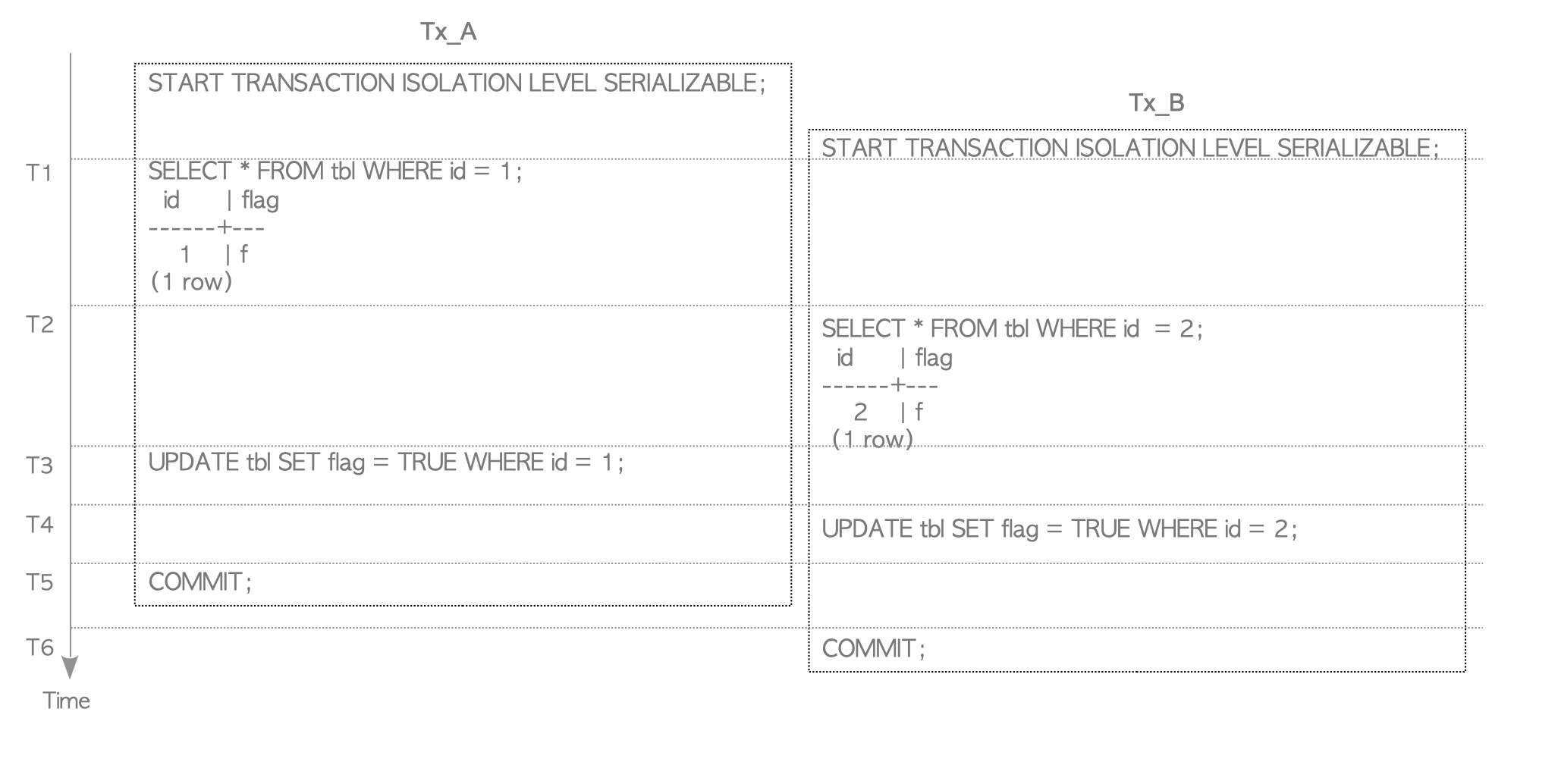
Figure 5.17. Other Write-Skew scenarios.
This Wiki explains several more complex anomalies.
5.9.4. False-Positive Serialization Anomalies
In SERIALIZABLE mode, the serializability of concurrent transactions is always fully guaranteed because false-negative serialization anomalies are never detected. However, under some circumstances, false-positive anomalies can be detected; therefore, users should keep this in mind when using SERIALIZABLE mode. In the following, the situations in which PostgreSQL detects false-positive anomalies are described.
5.9.4.1. False-Positive Scenario 1.
Figure 5.18 shows a scenario where a false-positive serialization anomaly occurs.

Figure 5.18. Scenario where false-positive serialization anomaly occurs.
When using sequential scan, as mentioned in the explanation of SIREAD locks, PostgreSQL creates a relation level SIREAD lock. Figure 5.19(1) shows SIREAD locks and rw-conflicts when PostgreSQL uses sequential scan. In this case, rw-conflicts C1 and C2, which are associated with the tbl’s SIREAD lock, are created, and they create a cycle in the precedence graph. Thus, a false-positive Write-Skew anomaly is detected (and either Tx_A or Tx_B will be aborted even though there is no conflict).
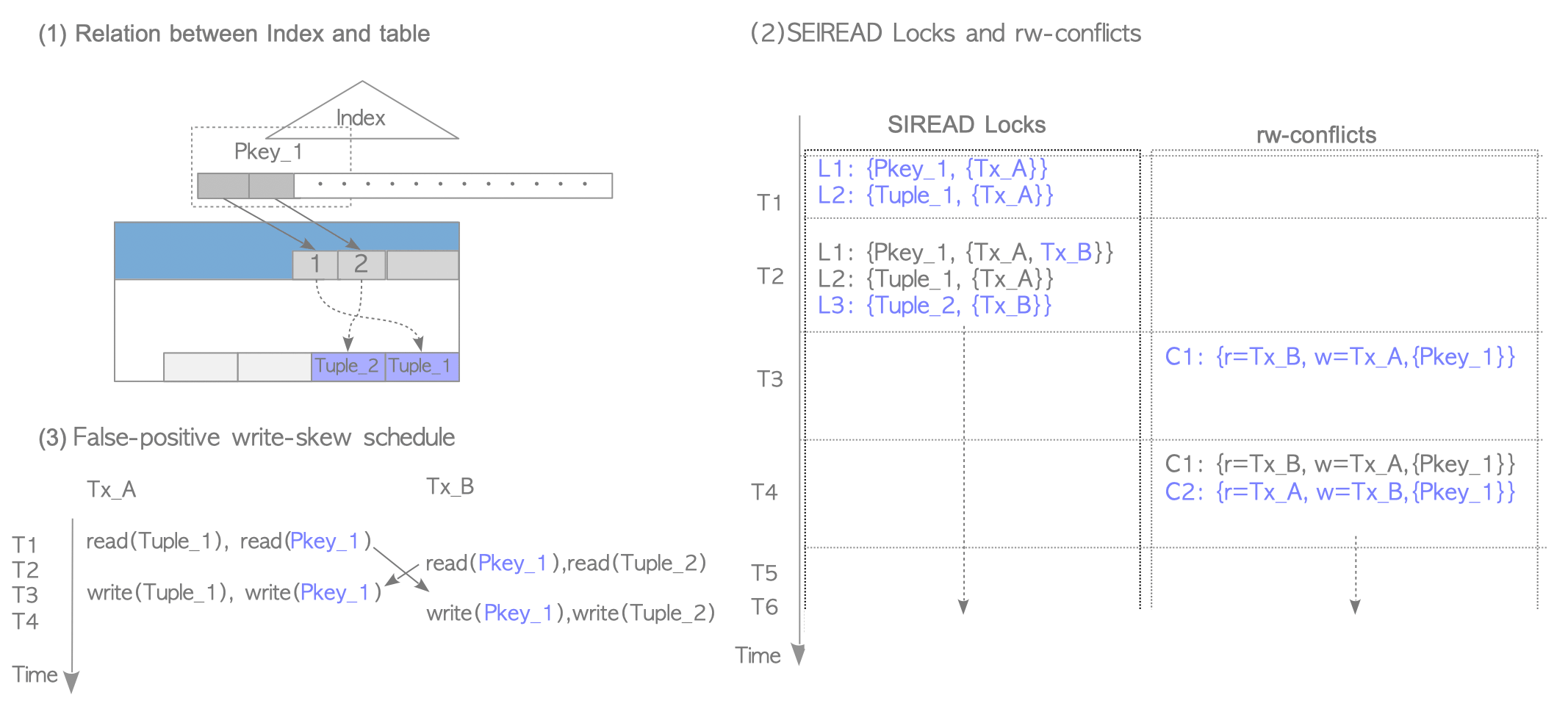
Figure 5.19. False-positive anomaly (1) - Using sequential scan.
5.9.4.2. False-Positive Scenario 2.
Even when using index scan, if both transactions Tx_A and Tx_B get the same index SIREAD lock, PostgreSQL detects a false-positive anomaly. Figure 5.20 shows this situation.
Figure 5.20. False-positive anomaly (2) - Index scan using the same index page.
Assume that the index page Pkey_1 contains two index items, one of which points to Tuple_1 and the other points to Tuple_2.
When Tx_A and Tx_B execute respective SELECT and UPDATE commands, Pkey_1 is read and written by both Tx_A and Tx_B. In this case, rw-conflicts C1 and C2, both of which are associated with Pkey_1, create a cycle in the precedence graph; thus, a false-positive Write-Skew anomaly is detected.
(If Tx_A and Tx_B get the SIREAD locks of different index pages, a false-positive is not detected and both transactions can be committed.)