3.5.1. Nested Loop Join
The nested loop join is the most fundamental join operation, and it can be used in all join conditions. PostgreSQL supports the nested loop join and five variations of it.
3.5.1.1. Nested Loop Join
The nested loop join does not need any start-up operation, so the start-up cost is 0:
$$ \begin{align} \text{'start-up cost'} = 0. \end{align} $$The run cost of the nested loop join is proportional to the product of the sizes of the outer and inner tables. In other words, the $ \text{‘run cost’} $ is $ O(N_{outer} \times N_{inner}) $, where $ N_{outer} $ and $ N_{inner} $ are the numbers of tuples of the outer table and the inner table, respectively. More precisely, the run cost is defined by the following equation:
$$ \begin{align} \text{'run cost'} = (\text{cpu_operator_cost} + \text{cpu_tuple_cost}) \times N_{outer} \times N_{inner} + C_{inner} \times N_{outer} + C_{outer} \end{align} $$where $ C_{outer} $ and $ C_{inner} $ are the scanning costs of the outer table and the inner table, respectively.
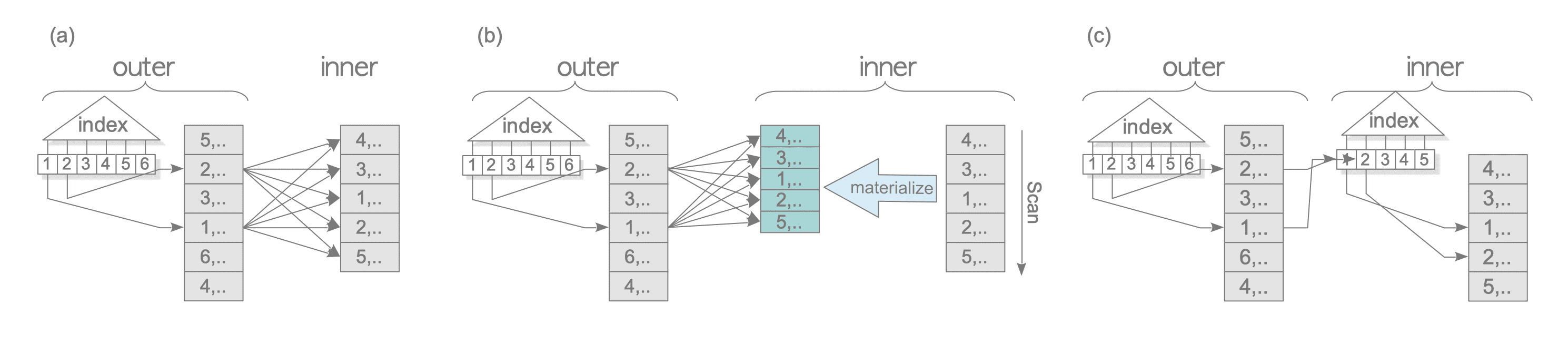
Figure. 3.19. Nested loop join.
The cost of the nested loop join is always estimated, but this join operation is rarely used because more efficient variations, which are described in the following, are usually used.
3.5.1.2. Materialized Nested Loop Join
The nested loop join described above has to scan all the tuples of the inner table whenever each tuple of the outer table is read. Since scanning the entire inner table for each outer table tuple is a costly process, PostgreSQL supports the materialized nested loop join to reduce the total scanning cost of the inner table.
Before running a nested loop join, the executor writes the inner table tuples to the work_mem or a temporary file by scanning the inner table once using the temporary tuple storage module described in below.
This has the potential to process the inner table tuples more efficiently than using the buffer manager, especially if at least all the tuples are written to work_mem.
Figure 3.20 illustrates how the materialized nested loop join performs. Scanning materialized tuples is internally called rescan.
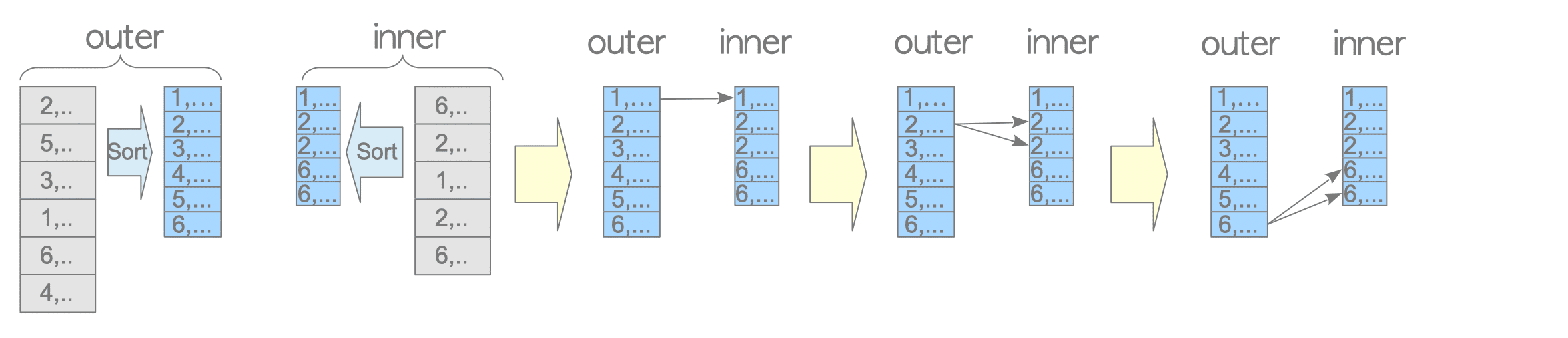
Figure 3.20. Materialized nested loop join.
PostgreSQL internally provides a temporary tuple storage module for materializing tables, creating batches in hybrid hash join and so on. This module is composed of the functions defined in tuplestore.c, and they store and read a sequence of tuples to/from work_mem or temporary files. The decision of whether to use the work_mem or temporary files depends on the total size of the tuples to be stored.
We will explore how the executor processes the plan tree of the materialized nested loop join and how the cost is estimated using the specific example shown below.
|
|
First, the operation of the executor is shown. The executor processes the displayed plan nodes as follows:
- Line 7: The executor materializes the inner table tbl_b by sequential scanning (Line 8).
- Line 4: The executor carries out the nested loop join operation; the outer table is tbl_a and the inner one is the materialized tbl_b.
In what follows, the costs of the ‘Materialize’ (Line 7) and ‘Nested Loop’ (Line 4) operations are estimated. Assume that the materialized inner tuples are stored in the work_mem.
Materialize:
There is no cost to start up, so the start-up cost is 0.
$$ \begin{align} \text{'start-up cost'} = 0 \end{align} $$The run cost is defined by the following equation:
$$ \begin{align} \text{'run cost'} = 2 \times \text{cpu_operator_cost} \times N_{inner} \end{align} $$Therefore,
$$ \begin{align} \text{'run cost'} = 2 \times 0.0025 \times 5000 = 25.0. \end{align} $$In addition, the total cost is the sum of the startup cost, the total cost of the sequential scan, and the run cost:
$$ \begin{align} \text{'total cost'} = (\text{'start-up cost'} + \text{'total cost of seq scan'}) + \text{'run cost'} \end{align} $$Therefore,
$$ \begin{align} \text{'total cost'} = (0.0 + 73.0) + 25.0 = 98.0. \end{align} $$(Materialized) Nested Loop:
There is no cost to start up, so the start-up cost is 0.
$$ \begin{align} \text{'start-up cost'} = 0 \end{align} $$Before estimating the run cost, we consider the rescan cost. This cost is defined by the following equation:
$$ \begin{align} \text{'rescan cost'} = \text{cpu_operator_cost} \times N_{inner} \end{align} $$In this case,
$$ \begin{align} \text{'rescan cost'} = (0.0025) \times 5000 = 12.5. \end{align} $$The run cost is defined by the following equation:
$$ \begin{align} \text{'run cost'} &= (\text{cpu_operator_cost} + \text{cpu_tuple_cost}) \times N_{inner} \times N_{outer} \\ &+ \text{'rescan cost'} \times (N_{outer} - 1) + C^{total}_{outer,seqscan} + C^{total}_{materialize} \end{align} $$where $ C_{outer,seqscan}^{total} $ is the total scan cost of the outer table and $ C^{total}_{materialize} $ is the total cost of the materialized. Therefore,
$$ \begin{align} \text{'run cost'} = (0.0025 + 0.01) \times 5000 \times 10000 + 12.5 \times (10000 - 1) + 145.0 + 98.0 = 750230.5. \end{align} $$3.5.1.3. Indexed Nested Loop Join
If there is an index on the inner table that can be used to look up the tuples satisfying the join condition for each tuple of the outer table, the planner will consider using this index for directly searching the inner table tuples instead of sequential scanning. This variation is called indexed nested loop join; see Figure 3.21. Despite the name, this algorithm can process all the tuples of the outer table in a single loop, so it can perform the join operation efficiently.
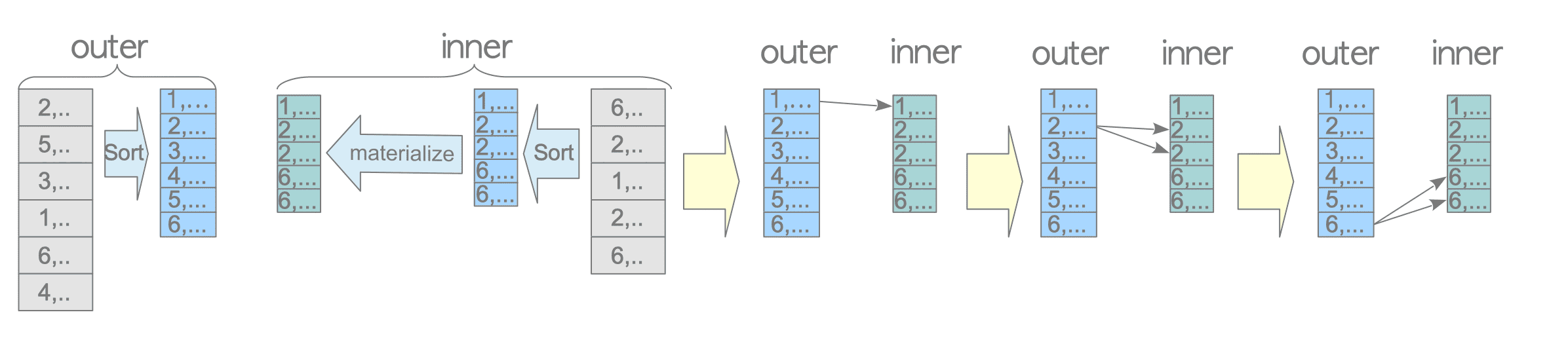
Figure 3.21. Indexed nested loop join.
A specific example of the indexed nested loop join is shown below.
|
|
In Line 6, the cost of accessing a tuple of the inner table is displayed. This is the cost of looking up the inner table if the tuple satisfies the index condition ‘$(\text{id} = \text{b.id})$’, which is shown in Line 7.
In the index condition ‘$(\text{id} = \text{b.id})$’ in Line 7, ‘$\text{b.id}$’ is the value of the outer table’s attribute used in the join condition. Whenever a tuple of the outer table is retrieved by sequential scanning, the index scan path in Line 6 looks up the inner tuples to be joined. In other words, whenever the outer table is passed as a parameter, this index scan path looks up the inner tuples that satisfy the join condition. Such an index path is called a parameterized (index) path. Details are described in README.
The start-up cost of this nested loop join is equal to the cost of the index scan in Line 6; thus,
$$ \begin{align} \text{'start-up cost'} = 0.285. \end{align} $$The total cost of the indexed nested loop join is defined by the following equation:
$$ \begin{align} \text{'total cost'} = (\text{cpu_tuple_cost} + C^{total}_{inner,parameterized}) \times N_{outer} + C^{run}_{outer,seqscan} \end{align} $$where $ C^{total}_{inner,parameterized} $ is the total cost of the parameterized inner index scan.
In this case,
$$ \begin{align} \text{'total cost'} = (0.01 + 0.3625) \times 5000 + 73.0 = 1935.5 \end{align} $$and the run cost is as follows:
$$ \begin{align} \text{'run cost'} = 1935.5 - 0.285 = 1935.215. \end{align} $$As shown above, the total cost of the indexed nested loop is $ O(N_{outer}) $.
3.5.1.4. Other Variations
If there is an index of the outer table and its attributes are involved in the join condition, it can be used for index scanning instead of the sequential scan of the outer table. In particular, if there is an index whose attribute can be used as an access predicate in the WHERE clause, the search range of the outer table is narrowed. This can drastically reduce the cost of the nested loop join.
PostgreSQL supports three variations of the nested loop join with an outer index scan. See Figure 3.22.
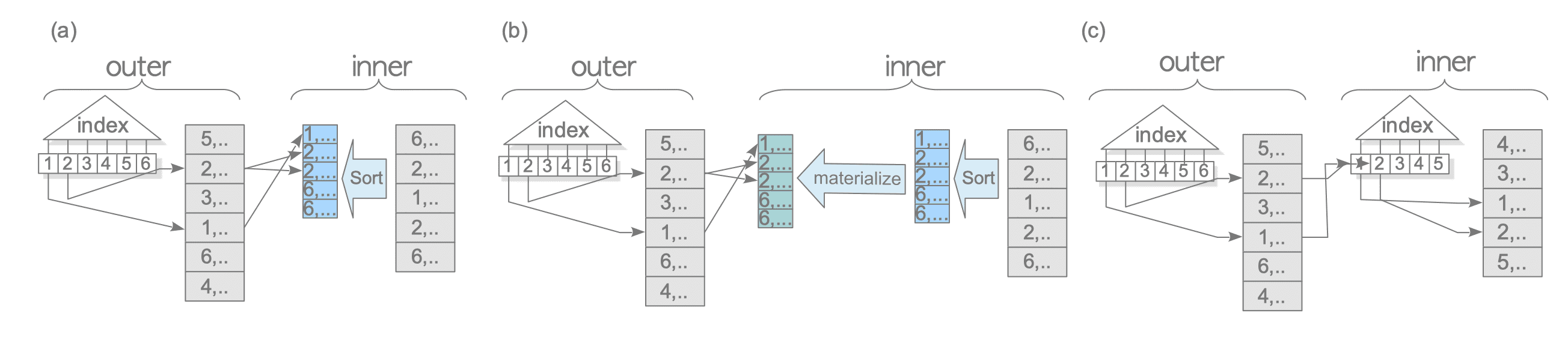
Figure 3.22. The three variations of the nested loop join with an outer index scan.
The results of these joins’ EXPLAIN are shown below:
(a) Nested loop join with outer index scan
testdb=# SET enable_hashjoin TO off;
SET
testdb=# SET enable_mergejoin TO off;
SET
testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND c.id = 500;
QUERY PLAN
--------------------------------------------------------------------------------
Nested Loop (cost=0.29..93.81 rows=1 width=16)
-> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..8.30 rows=1 width=8)
Index Cond: (id = 500)
-> Seq Scan on tbl_b b (cost=0.00..85.50 rows=1 width=8)
Filter: (id = 500)
(5 rows)(2) Materialized nested loop join with outer index scan
testdb=# SET enable_hashjoin TO off;
SET
testdb=# SET enable_mergejoin TO off;
SET
testdb=# EXPLAIN SELECT * FROM tbl_c AS c, tbl_b AS b WHERE c.id = b.id AND c.id < 40 AND b.id < 10;
QUERY PLAN
---------------------------------------------------------------------------------
Nested Loop (cost=0.29..99.76 rows=1 width=16)
Join Filter: (c.id = b.id)
-> Index Scan using tbl_c_pkey on tbl_c c (cost=0.29..8.97 rows=39 width=8)
Index Cond: (id < 40)
-> Materialize (cost=0.00..85.55 rows=9 width=8)
-> Seq Scan on tbl_b b (cost=0.00..85.50 rows=9 width=8)
Filter: (id < 10)
(7 rows)(3) Indexed nested loop join with outer index scan
testdb=# SET enable_hashjoin TO off;
SET
testdb=# SET enable_mergejoin TO off;
SET
testdb=# EXPLAIN SELECT * FROM tbl_a AS a, tbl_d AS d WHERE a.id = d.id AND a.id < 40;
QUERY PLAN
---------------------------------------------------------------------------------
Nested Loop (cost=0.57..173.06 rows=20 width=16)
-> Index Scan using tbl_a_pkey on tbl_a a (cost=0.29..8.97 rows=39 width=8)
Index Cond: (id < 40)
-> Index Scan using tbl_d_pkey on tbl_d d (cost=0.28..4.20 rows=1 width=8)
Index Cond: (id = a.id)
(5 rows)