9.4. Internal Layout of XLOG Record
An XLOG record comprises a general header portion and each associated data portion. The first subsection describes the header structure. The remaining two subsections explain the structure of the data portion in versions 9.4 and earlier, and version 9.5, respectively. (The data format changed in version 9.5.)
9.4.1. Header Portion of XLOG Record
All XLOG records have a general header portion defined by the XLogRecord structure. Here, the structure of 9.4 and earlier versions is shown below, although it has been changed in version 9.5.
typedef struct XLogRecord
{
uint32 xl_tot_len; /* total len of entire record */
TransactionId xl_xid; /* xact id */
uint32 xl_len; /* total len of rmgr data. This variable was removed in ver.9.5. */
uint8 xl_info; /* flag bits, see below */
RmgrId xl_rmid; /* resource manager for this record */
/* 2 bytes of padding here, initialize to zero */
XLogRecPtr xl_prev; /* ptr to previous record in log */
pg_crc32 xl_crc; /* CRC for this record */
} XLogRecord;In versions 9.5 or later, one variable (xl_len) has been removed the XLogRecord structure to refine the XLOG record format, which reduced the size by a few bytes.
Apart from two variables, most of the variables are so obvious that they do not need to be described.
Both xl_rmid and xl_info are variables related to resource managers, which are collections of operations associated with the WAL feature, such as writing and replaying of XLOG records. The number of resource managers tends to increase with each PostgreSQL version. Version 10 contains the following:
| Operation | Resource manager |
|---|---|
| Heap tuple operations | RM_HEAP, RM_HEAP2 |
| Index operations | RM_BTREE, RM_HASH, RM_GIN, RM_GIST, RM_SPGIST, RM_BRIN |
| Sequence operations | RM_SEQ |
| Transaction operations | RM_XACT, RM_MULTIXACT, RM_CLOG, RM_XLOG, RM_COMMIT_TS |
| Tablespace operations | RM_SMGR, RM_DBASE, RM_TBLSPC, RM_RELMAP |
| replication and hot standby operations | RM_STANDBY, RM_REPLORIGIN, RM_GENERIC_ID, RM_LOGICALMSG_ID |
Here are some representative examples of how resource managers work:
-
If an INSERT statement is issued, the header variables xl_rmid and xl_info of its XLOG record are set to ‘RM_HEAP’ and ‘XLOG_HEAP_INSERT’, respectively. When recovering the database cluster, the RM_HEAP’s function heap_xlog_insert() is selected according to the xl_info and replays this XLOG record.
-
Similarly, for an UPDATE statement, the header variable xl_info of the XLOG record is set to ‘XLOG_HEAP_UPDATE’, and the RM_HEAP’s function heap_xlog_update() replays its record when the database recovers.
-
When a transaction commits, the header variables xl_rmid and xl_info of its XLOG record are set to ‘RM_XACT’ and ‘XLOG_XACT_COMMIT’, respectively. When recovering the database cluster, the function xact_redo_commit() replays this record.
XLogRecord structure in versions 9.4 or earlier is defined in src/include/access/xlog.h and that of versions 9.5 or later is defined in src/include/access/xlogrecord.h.
The heap_xlog_insert and heap_xlog_update are defined in src/backend/access/heap/heapam.c; while the function xact_redo_commit is defined in src/backend/access/transam/xact.c.
9.4.2. Data Portion of XLOG Record (versions 9.4 or earlier)
The data portion of an XLOG record can be classified into either a backup block (which contains the entire page) or a non-backup block (which contains different data depending on the operation).
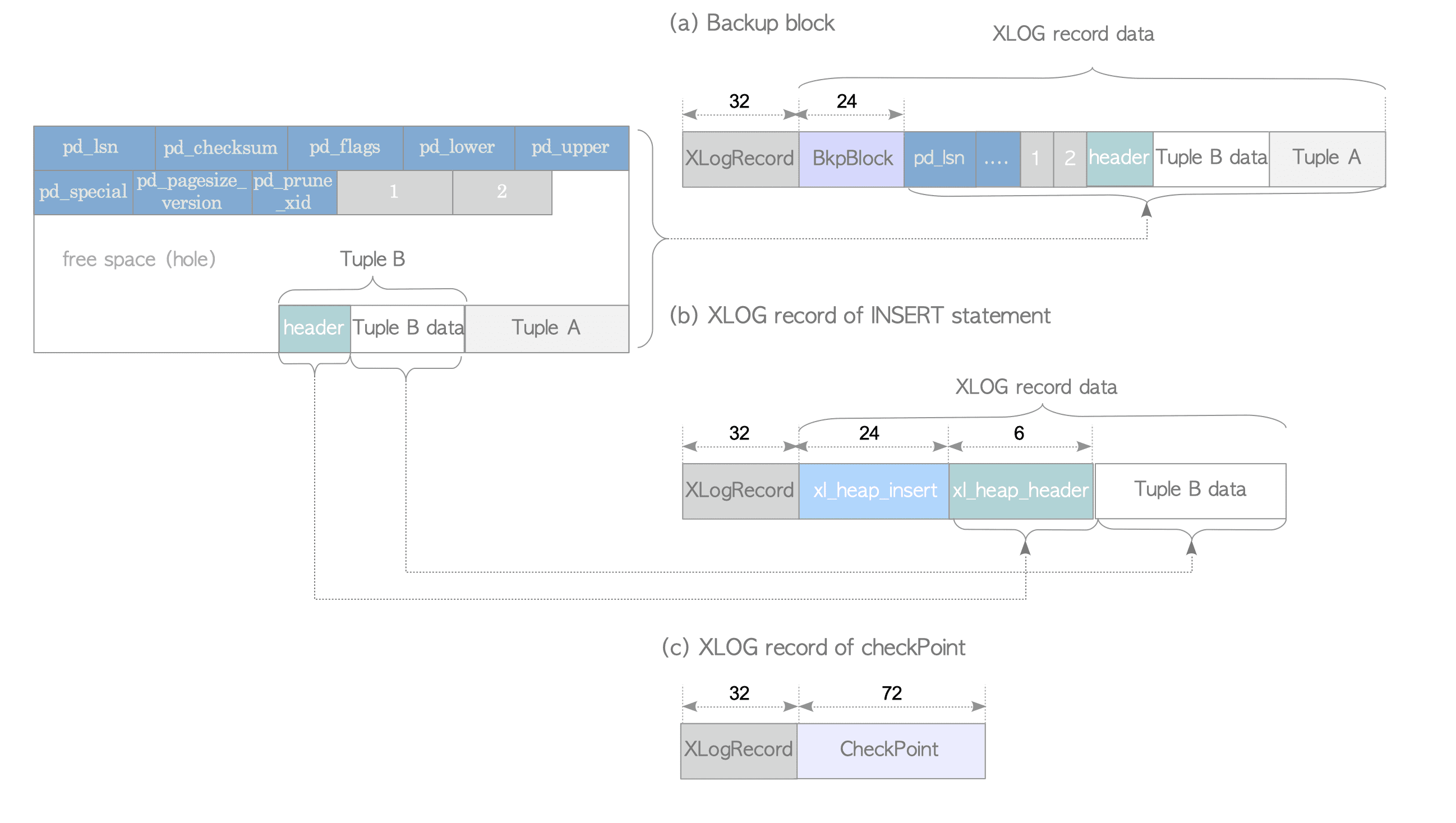
Figure 9.8. Examples of XLOG records (versions 9.4 or earlier).
The internal layouts of XLOG records are described below, using some specific examples.
9.4.2.1. Backup Block
A backup block is shown in Figure 9.8(a). It is composed of two data structures and one data object:
-
The XLogRecord structure (header portion).
-
The
BkpBlockstructure. -
The entire page, except for its free space.
The BkpBlock structure contains the variables that identify the page in the database cluster (i.e., the relfilenode and the fork number of the relation that contains the page, and the page’s block number),
as well as the starting position and length of the page’s free space.
9.4.2.2. Non-Backup Block
In non-backup blocks, the layout of the data portion differs depending on the operation. Here, the XLOG record for an INSERT statement is explained as a representative example. See Figure 9.8(b). In this case, the XLOG record for the INSERT statement is composed of two data structures and one data object:
-
The XLogRecord (header-portion) structure.
-
The
xl_heap_insertstructure. -
The inserted tuple, with a few bytes removed.
The xl_heap_insert structure contains the variables that identify the inserted tuple in the database cluster (i.e., the relfilenode of the table that contains this tuple, and the tuple’s tid), as well as a visibility flag of this tuple.
The reason to remove a few bytes from inserted tuple is described in the source code comment of the structure xl_heap_header:
We don’t store the whole fixed part (HeapTupleHeaderData) of an inserted or updated tuple in WAL; we can save a few bytes by reconstructing the fields that are available elsewhere in the WAL record, or perhaps just plain needn’t be reconstructed.
One more example will be shown here. See Figure 9.8(c). The XLOG record for a checkpoint record is quite simple; it is composed of two data structures:
- the XLogRecord structure (header-portion).
- the Checkpoint structure, which contains its checkpoint information (see more detail in Section 9.7).
The xl_heap_header structure (versions 9.4 or earlier) is defined in src/include/access/heapam_xlog.h while the CheckPoint structure is defined in src/include/catalog/pg_control.h.
9.4.3. Data Portion of XLOG Record (versions 9.5 or later)
In versions 9.4 or earlier, there was no common format for XLOG records, so each resource manager had to define its own format. This made it increasingly difficult to maintain the source code and implement new features related to WAL. To address this issue, a common structured format that is independent of resource managers was introduced in version 9.5.
The data portion of an XLOG record can be divided into two parts: header and data. See Figure 9.9.
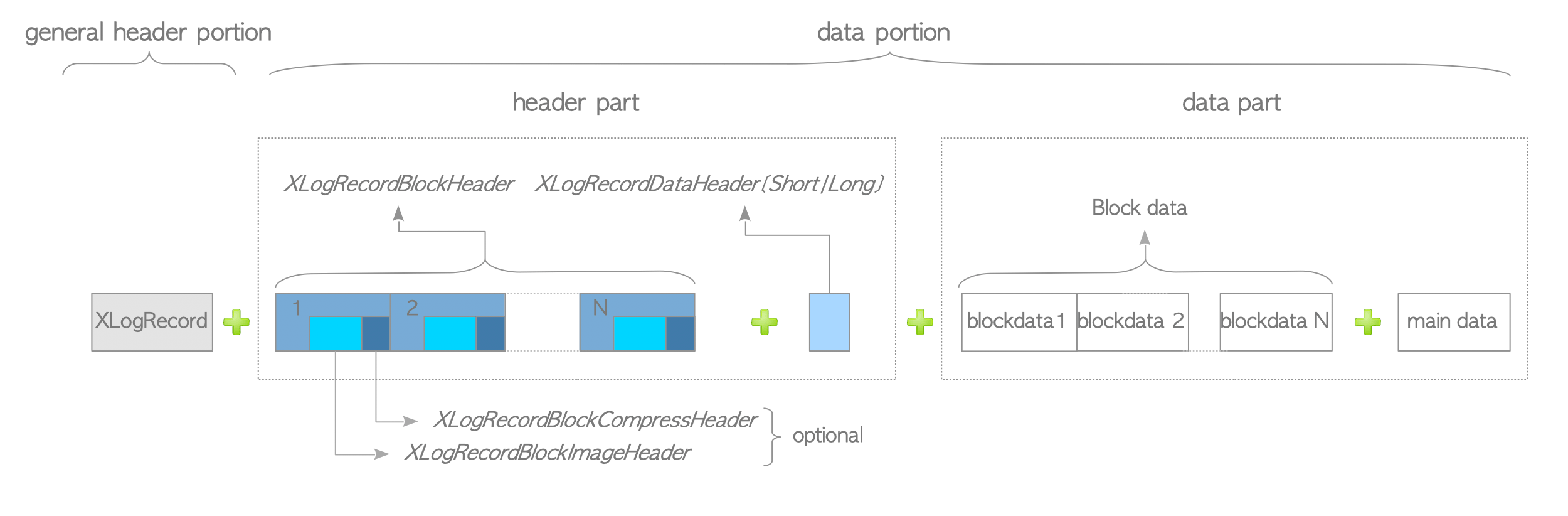
Figure 9.9. Common XLOG record format.
The header part contains zero or more XLogRecordBlockHeaders and zero or one XLogRecordDataHeaderShort (or XLogRecordDataHeaderLong).
It must contain at least one of these.
When the record stores a full-page image (i.e., a backup block), the XLogRecordBlockHeader includes the XLogRecordBlockImageHeader, and also includes the XLogRecordBlockCompressHeader if its block is compressed.
The data part is composed of zero or more block data and zero or one main data, which correspond to the XLogRecordBlockHeader(s) and to the XLogRecordDataHeader, respectively.
In versions 9.5 or later, full-page images within XLOG records can be compressed using the LZ compression method by setting the parameter wal_compression = enable. In that case, the XLogRecordBlockCompressHeader structure will be added.
This feature has two advantages and one disadvantage. The advantages are reducing the I/O cost for writing records and suppressing the consumption of WAL segment files. The disadvantage is consuming much CPU resource to compress.
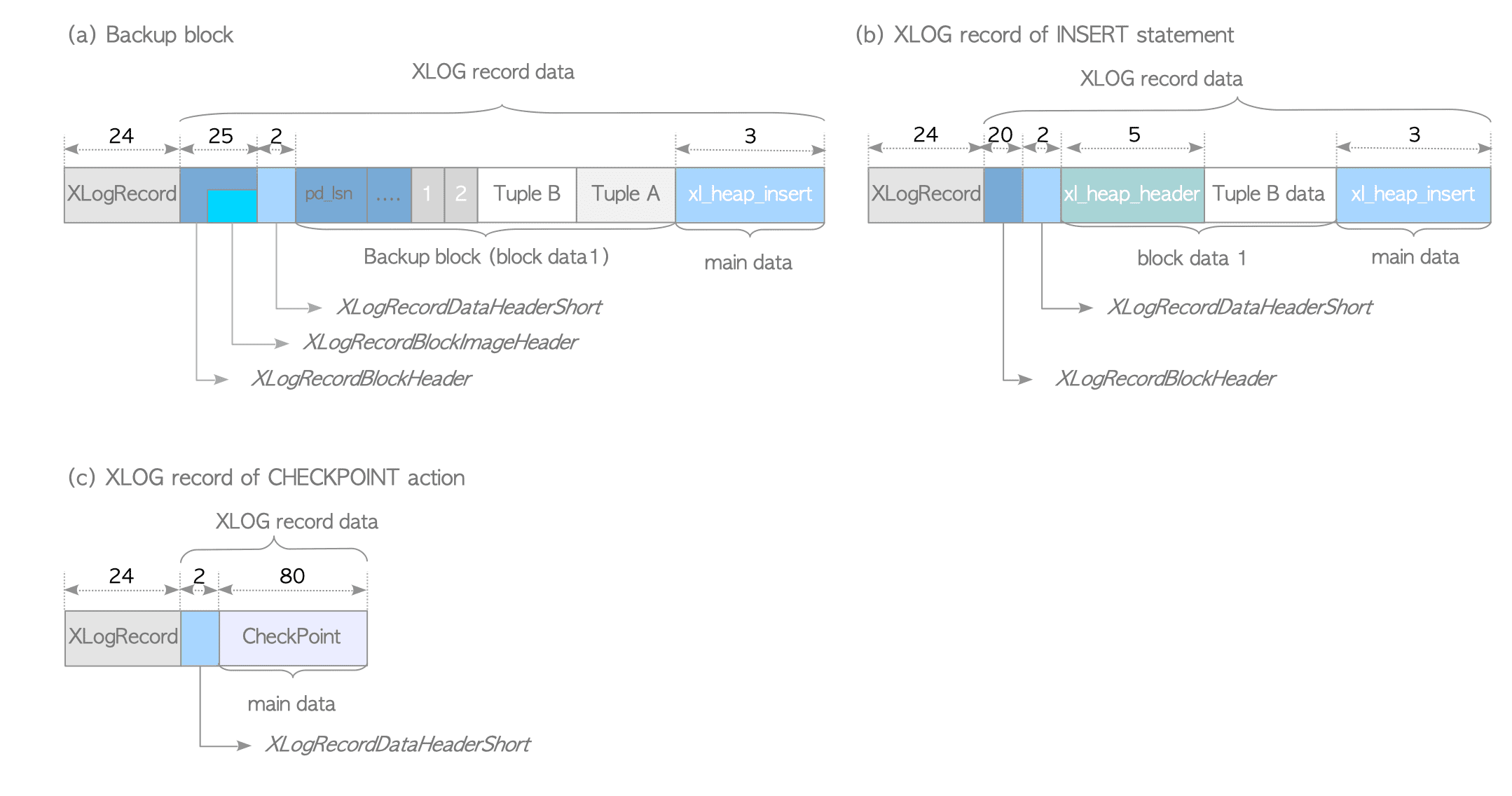
Figure 9.10. Examples of XLOG records (versions 9.5 or later).
Some specific examples are shown below, as in the previous subsection.
9.4.3.1. Backup Block
The backup block created by an INSERT statement is shown in Figure 9.10(a). It is composed of four data structures and one data object:
- the XLogRecord structure (header-portion).
- the XLogRecordBlockHeader structure, including one LogRecordBlockImageHeader structure.
- the XLogRecordDataHeaderShort structure.
- a backup block (block data).
- the xl_heap_insert structure (main data).
The XLogRecordBlockHeader structure contains the variables to identify the block in the database cluster (the relfilenode, the fork number, and the block number). The XLogRecordImageHeader structure contains the length of this block and offset number. (These two header structures together can store the same data as the BkBlock structure used until version 9.4.)
The XLogRecordDataHeaderShort structure stores the length of the xl_heap_insert structure, which is the main data of the record. (See below.)
The main data of an XLOG record that contains a full-page image is not used except in some special cases, such as logical decoding and speculative insertions. It is ignored when the record is replayed, making it redundant data. This may be improved in the future.
In addition, the main data of backup block records depends on the statements that create them. For example, an UPDATE statement appends xl_heap_lock or xl_heap_updated.
9.4.3.2. Non-Backup Block
Next, we will describe the non-backup block record created by the INSERT statement (see Figure 9.10(b)). It is composed of four data structures and one data object:
- the XLogRecord structure (header-portion).
- the XLogRecordBlockHeader structure.
- the XLogRecordDataHeaderShort structure.
- an inserted tuple (to be exact, a xl_heap_header structure and an inserted data entire).
- the
xl_heap_insertstructure (main data).
The XLogRecordBlockHeader structure contains three values (the relfilenode, the fork number, and the block number) to specify the block that the tuple was inserted into, and the length of the data portion of the inserted tuple. The XLogRecordDataHeaderShort structure contains the length of the new xl_heap_insert structure, which is the main data of this record.
The new xl_heap_insert structure contains only two values: the offset number of this tuple within the block, and a visibility flag. It became very simple because the XLogRecordBlockHeader structure stores most of the data that was contained in the old xl_heap_insert structure.
As the final example, a checkpoint record is shown in the Figure 9.10(c). It is composed of three data structures:
- the XLogRecord structure (header-portion).
- the XLogRecordDataHeaderShort structure contained of the main data length.
- the structure CheckPoint (main data).
The structure xl_heap_header is defined in src/include/access/htup.h and the CheckPoint structure is defined in src/include/catalog/pg_control.h.
The new XLOG format, while more complex for human interpretation, is optimized for parser efficiency. Additionally, many XLOG record types are now smaller in size.
The sizes of the main structures are shown in Figures 9.8 and 9.10, allowing for the calculation and comparison of record sizes1.
-
While the size of the new checkpoint is larger than the previous one, it includes more variables. ↩︎