3.5.4. Join Access Paths and Join Nodes
3.5.4.1. Join Access Paths
The JoinPath structure is an access path for the nested loop join.
Other join access paths, such as MergePath and HashPath,
are based on it.
All join access paths are illustrated below, without explanation.
typedef JoinPath NestPath;
/*
* JoinType -
* enums for types of relation joins
*
* JoinType determines the exact semantics of joining two relations using
* a matching qualification. For example, it tells what to do with a tuple
* that has no match in the other relation.
*
* This is needed in both parsenodes.h and plannodes.h, so put it here...
*/
typedef enum JoinType
{
/*
* The canonical kinds of joins according to the SQL JOIN syntax. Only
* these codes can appear in parser output (e.g., JoinExpr nodes).
*/
JOIN_INNER, /* matching tuple pairs only */
JOIN_LEFT, /* pairs + unmatched LHS tuples */
JOIN_FULL, /* pairs + unmatched LHS + unmatched RHS */
JOIN_RIGHT, /* pairs + unmatched RHS tuples */
/*
* Semijoins and anti-semijoins (as defined in relational theory) do not
* appear in the SQL JOIN syntax, but there are standard idioms for
* representing them (e.g., using EXISTS). The planner recognizes these
* cases and converts them to joins. So the planner and executor must
* support these codes. NOTE: in JOIN_SEMI output, it is unspecified
* which matching RHS row is joined to. In JOIN_ANTI output, the row is
* guaranteed to be null-extended.
*/
JOIN_SEMI, /* 1 copy of each LHS row that has match(es) */
JOIN_ANTI, /* 1 copy of each LHS row that has no match */
JOIN_RIGHT_ANTI, /* 1 copy of each RHS row that has no match */
/*
* These codes are used internally in the planner, but are not supported
* by the executor (nor, indeed, by most of the planner).
*/
JOIN_UNIQUE_OUTER, /* LHS path must be made unique */
JOIN_UNIQUE_INNER /* RHS path must be made unique */
/*
* We might need additional join types someday.
*/
} JoinType;
/*
* All join-type paths share these fields.
*/
typedef struct JoinPath
{
pg_node_attr(abstract)
Path path;
JoinType jointype;
bool inner_unique; /* each outer tuple provably matches no more
* than one inner tuple */
Path *outerjoinpath; /* path for the outer side of the join */
Path *innerjoinpath; /* path for the inner side of the join */
List *joinrestrictinfo; /* RestrictInfos to apply to join */
/*
* See the notes for RelOptInfo and ParamPathInfo to understand why
* joinrestrictinfo is needed in JoinPath, and can't be merged into the
* parent RelOptInfo.
*/
} JoinPath;/*
* A mergejoin path has these fields.
*
* Unlike other path types, a MergePath node doesn't represent just a single
* run-time plan node: it can represent up to four. Aside from the MergeJoin
* node itself, there can be a Sort node for the outer input, a Sort node
* for the inner input, and/or a Material node for the inner input. We could
* represent these nodes by separate path nodes, but considering how many
* different merge paths are investigated during a complex join problem,
* it seems better to avoid unnecessary palloc overhead.
*
* path_mergeclauses lists the clauses (in the form of RestrictInfos)
* that will be used in the merge.
*
* Note that the mergeclauses are a subset of the parent relation's
* restriction-clause list. Any join clauses that are not mergejoinable
* appear only in the parent's restrict list, and must be checked by a
* qpqual at execution time.
*
* outersortkeys (resp. innersortkeys) is NIL if the outer path
* (resp. inner path) is already ordered appropriately for the
* mergejoin. If it is not NIL then it is a PathKeys list describing
* the ordering that must be created by an explicit Sort node.
*
* skip_mark_restore is true if the executor need not do mark/restore calls.
* Mark/restore overhead is usually required, but can be skipped if we know
* that the executor need find only one match per outer tuple, and that the
* mergeclauses are sufficient to identify a match. In such cases the
* executor can immediately advance the outer relation after processing a
* match, and therefore it need never back up the inner relation.
*
* materialize_inner is true if a Material node should be placed atop the
* inner input. This may appear with or without an inner Sort step.
*/
typedef struct MergePath
{
JoinPath jpath;
List *path_mergeclauses; /* join clauses to be used for merge */
List *outersortkeys; /* keys for explicit sort, if any */
List *innersortkeys; /* keys for explicit sort, if any */
bool skip_mark_restore; /* can executor skip mark/restore? */
bool materialize_inner; /* add Materialize to inner? */
} MergePath;/*
* A hashjoin path has these fields.
*
* The remarks above for mergeclauses apply for hashclauses as well.
*
* Hashjoin does not care what order its inputs appear in, so we have
* no need for sortkeys.
*/
typedef struct HashPath
{
JoinPath jpath;
List *path_hashclauses; /* join clauses used for hashing */
int num_batches; /* number of batches expected */
Cardinality inner_rows_total; /* total inner rows expected */
} HashPath;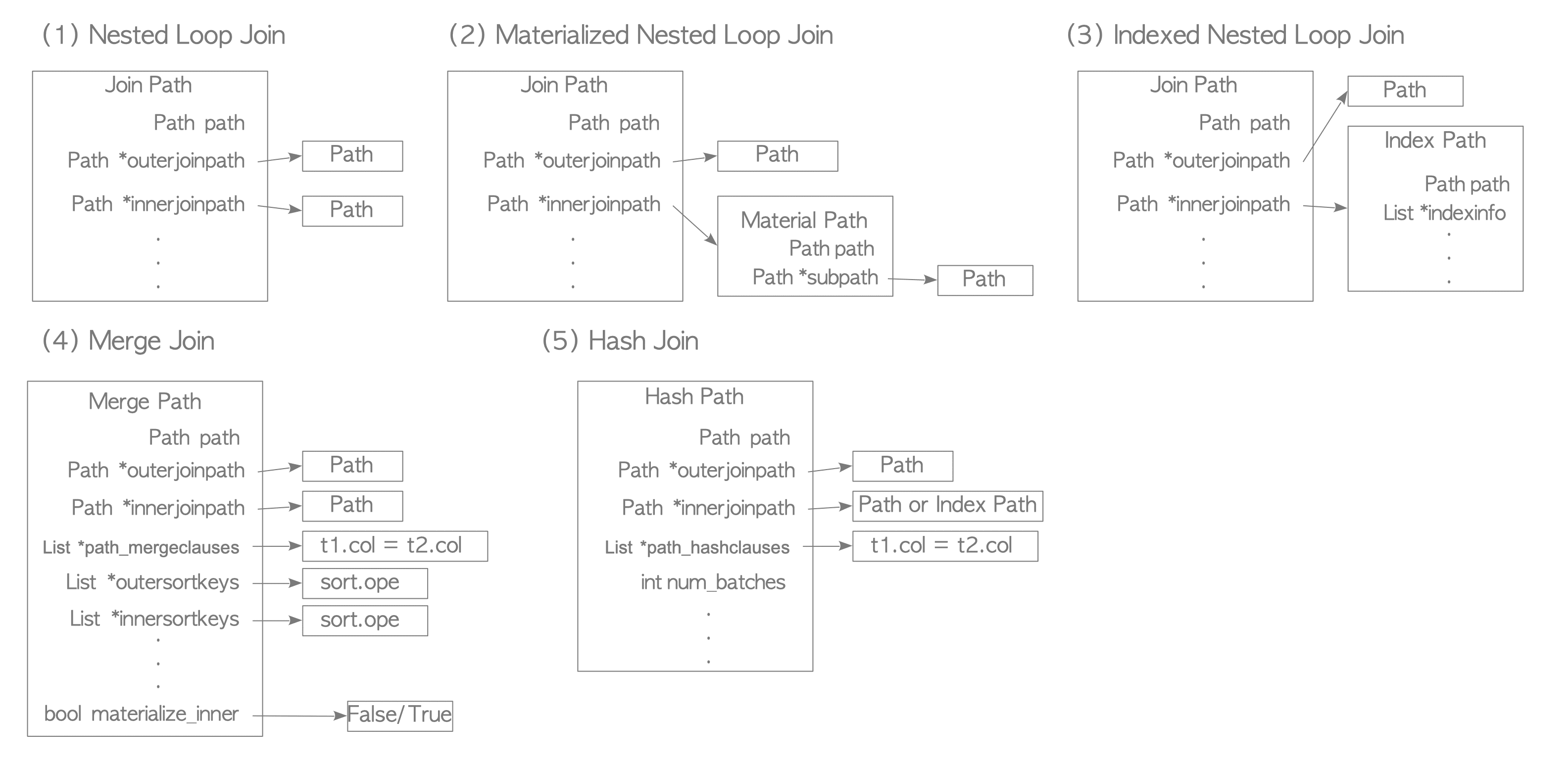
Figure 3.33. Join access paths.
3.5.4.2. Join Nodes
This subsection shows the three join nodes: NestedLoopNode, MergeJoinNode and HashJoinNode, without explanation.
They are all based on the JoinNode.
/* ----------------
* Join node
*
* jointype: rule for joining tuples from left and right subtrees
* inner_unique each outer tuple can match to no more than one inner tuple
* joinqual: qual conditions that came from JOIN/ON or JOIN/USING
* (plan.qual contains conditions that came from WHERE)
*
* When jointype is INNER, joinqual and plan.qual are semantically
* interchangeable. For OUTER jointypes, the two are *not* interchangeable;
* only joinqual is used to determine whether a match has been found for
* the purpose of deciding whether to generate null-extended tuples.
* (But plan.qual is still applied before actually returning a tuple.)
* For an outer join, only joinquals are allowed to be used as the merge
* or hash condition of a merge or hash join.
*
* inner_unique is set if the joinquals are such that no more than one inner
* tuple could match any given outer tuple. This allows the executor to
* skip searching for additional matches. (This must be provable from just
* the joinquals, ignoring plan.qual, due to where the executor tests it.)
* ----------------
*/
typedef struct Join
{
pg_node_attr(abstract)
Plan plan;
JoinType jointype;
bool inner_unique;
List *joinqual; /* JOIN quals (in addition to plan.qual) */
} Join;/* ----------------
* nest loop join node
*
* The nestParams list identifies any executor Params that must be passed
* into execution of the inner subplan carrying values from the current row
* of the outer subplan. Currently we restrict these values to be simple
* Vars, but perhaps someday that'd be worth relaxing. (Note: during plan
* creation, the paramval can actually be a PlaceHolderVar expression; but it
* must be a Var with varno OUTER_VAR by the time it gets to the executor.)
* ----------------
*/
typedef struct NestLoop
{
Join join;
List *nestParams; /* list of NestLoopParam nodes */
} NestLoop;
typedef struct NestLoopParam
{
pg_node_attr(no_equal, no_query_jumble)
NodeTag type;
int paramno; /* number of the PARAM_EXEC Param to set */
Var *paramval; /* outer-relation Var to assign to Param */
} NestLoopParam;/* ----------------
* merge join node
*
* The expected ordering of each mergeable column is described by a btree
* opfamily OID, a collation OID, a direction (BTLessStrategyNumber or
* BTGreaterStrategyNumber) and a nulls-first flag. Note that the two sides
* of each mergeclause may be of different datatypes, but they are ordered the
* same way according to the common opfamily and collation. The operator in
* each mergeclause must be an equality operator of the indicated opfamily.
* ----------------
*/
typedef struct MergeJoin
{
Join join;
/* Can we skip mark/restore calls? */
bool skip_mark_restore;
/* mergeclauses as expression trees */
List *mergeclauses;
/* these are arrays, but have the same length as the mergeclauses list: */
/* per-clause OIDs of btree opfamilies */
Oid *mergeFamilies pg_node_attr(array_size(mergeclauses));
/* per-clause OIDs of collations */
Oid *mergeCollations pg_node_attr(array_size(mergeclauses));
/* per-clause ordering (ASC or DESC) */
int *mergeStrategies pg_node_attr(array_size(mergeclauses));
/* per-clause nulls ordering */
bool *mergeNullsFirst pg_node_attr(array_size(mergeclauses));
} MergeJoin;/* ----------------
* hash join node
* ----------------
*/
typedef struct HashJoin
{
Join join;
List *hashclauses;
List *hashoperators;
List *hashcollations;
/*
* List of expressions to be hashed for tuples from the outer plan, to
* perform lookups in the hashtable over the inner plan.
*/
List *hashkeys;
} HashJoin;