1.1. Logical Structure of Database Cluster
A database cluster is a collection of databases managed by a PostgreSQL server. If you are hearing this definition for the first time, you might be wondering what it means. The term ‘database cluster’ in PostgreSQL does not mean ‘a group of database servers’. A PostgreSQL server runs on a single host and manages a single database cluster.
Figure 1.1 shows the logical structure of a database cluster. A database is a collection of database objects. In the relational database theory, a database object is a data structure used to store or reference data. A (heap) table is a typical example, and there are many others, such as indexes, sequences, views, functions. In PostgreSQL, databases themselves are also database objects and are logically separated from each other. All other database objects (e.g., tables, indexes, etc) belong to their respective databases.
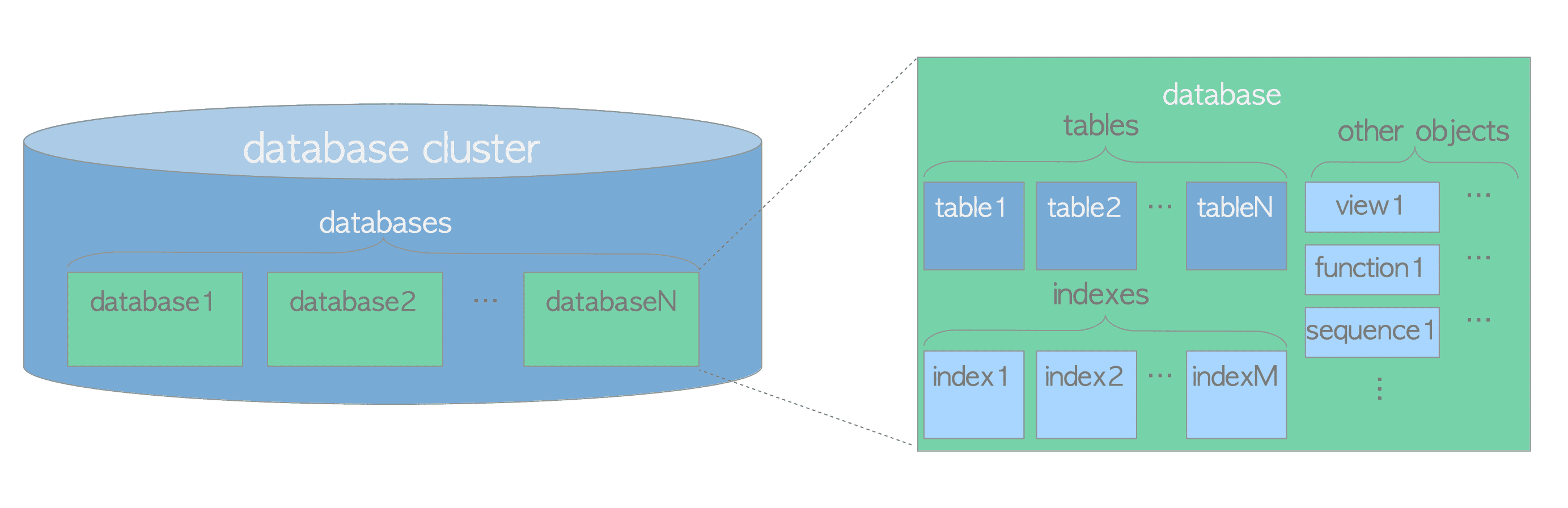
Figure 1.1. Logical structure of a database cluster.
All the database objects in PostgreSQL are internally managed by respective object identifiers (OIDs), which are unsigned 4-byte integers. The relations between database objects and their respective OIDs are stored in appropriate system catalogs, depending on the type of objects. For example, OIDs of databases and heap tables are stored in pg_database and pg_class, respectively.
To find the desired OIDs, execute the following queries:
sampledb=# SELECT datname, oid FROM pg_database WHERE datname = 'sampledb';
datname | oid
----------+-------
sampledb | 16384
(1 row)
sampledb=# SELECT relname, oid FROM pg_class WHERE relname = 'sampletbl';
relname | oid
-----------+-------
sampletbl | 18740
(1 row)Until PostgreSQL 11 (2018), the database could automatically assign a unique OID (Object Identifier) to every row in user tables, just as it does for tables and indexes.
This feature originated from PostgreSQL’s predecessor, POSTGRES, which was designed as an “Object-Relational Database.” Influenced by the cutting-edge object-oriented concepts of the time, the underlying philosophy was to treat everything — not just tables, but also the stored data (tuples) themselves — as “objects” with their own identities.
Below is an example of implicit OID assignment in Version 8.0:
testdb=# SELECT version();
version
-------------------------------------------------------------------------------------------------------------
PostgreSQL 8.0.26 on arm-apple-darwin24.5.0, compiled by GCC Apple clang version 17.0.0 (clang-1700.0.13.5)
(1 row)
testdb=# \d tbl
Table "public.tbl"
Column | Type | Modifiers
--------+---------+-----------
id | integer |
data | text |
testdb=# SELECT * FROM tbl;
id | data
----+------
1 | a
2 | b
3 | c
(3 rows)
testdb=# SELECT oid, * FROM tbl;
oid | id | data
-------+----+------
17236 | 1 | a
17237 | 2 | b
17238 | 3 | c
(3 rows)As shown here, an OID was automatically assigned to every row.
However, accessing data using internal OIDs conflicted with the core principles of Relational Databases (RDB), which focus on manipulating data based on its actual values. Combined with the physical limitations of the 32-bit OID format, this feature became impractical for most use cases relatively early on.
For a long time, it was maintained only for backward compatibility. After a lengthy transition period, row-level OIDs were disabled by default in version 8.1 (2005) and finally removed in version 12 (2019).