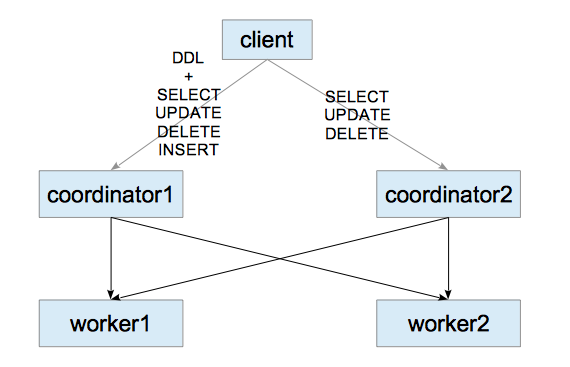
In the standard setup of Citus, it has one coordinator, so it is the single point of failure and the bottle neck of the system.
To solve these disadvantages, I built a multi-coordinator using Streaming Replication, which is the built-in replication feature of PostgreSQL.
In this blog, I install and run all postgres servers: two coordinators and two workers, in a single host.
1. Installing PostgreSQL
Download the latest postgresql source code, and install to /usr/local/pgsql.
# cd /usr/local/src
# tar xvfj postgresql-9.6.3.tar.bz2
# cd postgresql-9.6.3
# ./configure —prefix=/usr/local/pgsql
# make && make install
Add the path /usr/local/pgsql/bin to the environment variable PATH.
# export PATH=/usr/local/pgsql/bin:$PATH
2. Installing Citus
# cd /usr/local/src/postgresql-9.6.3/contrib
# git clone https://github.com/citusdata/citus.git
# cd citus
# configure
# make && make install
3. Creating servers
At first, create one coordinator and two workers.
3.1. Creating the database clusters
Create citus-sr subdirectory, and execute initdb command to create each database cluster.
# cd /usr/local/pgsql
# mkdir citus-sr
# initdb -D citus-sr/coordinator1
# initdb -D citus-sr/worker1
# initdb -D citus-sr/worker2
3.2. Editing postgresql.conf
Edit each postgresql.conf.
coordinator1
listen_addresses = '*'
wal_level = replica
max_wal_senders = 3
hot_standby = on
shared_preload_libraries = 'citus'
worker1
port = 9701
shared_preload_libraries = 'citus'
worker2
port = 9702
shared_preload_libraries = 'citus'
3.3. Starting servers
Start three servers.
# pg_ctl -D citus-sr/coordinator1 -l coordinator1_logfile start
# pg_ctl -D citus-sr/worker1 -l worker1_logfile start
# pg_ctl -D citus-sr/worker2 -l worker2_logfile start
3.4. Creating extension
Execute CREATE EXTENTION command in each server.
# psql -c "CREATE EXTENSION citus;"
# psql -p 9701 -c "CREATE EXTENSION citus;"
# psql -p 9702 -c "CREATE EXTENSION citus;"
3.5. Adding worker nodes
Add workers to the coordinator1.
# psql -c "SELECT * from master_add_node('localhost', 9701);"
# psql -c "SELECT * from master_add_node('localhost', 9702);"
# psql -c "select * from master_get_active_worker_nodes();"
node_name | node_port
-----------+-----------
localhost | 9701
localhost | 9702
(2 rows)
4. Creating the coordinator’s standby server
Create the coordinator2 server which is a replication of the coordinator1.
At first, create the coordinator2’s database cluster using the pg_basebackup utility.
pg_basebackup -D /usr/local/pgsql/citus-sr/coordinator2 -X stream --progress -U postgres -R
Next, edit the postgresql.conf and recovery.conf files where are located in the citus-sr/coordinator2 subdirectory.
postgresql.conf
port = 5433
recovery.conf
standby_mode = 'on'
primary_conninfo = 'user=postgres port=5432 sslmode=disable sslcompression=1'
Last, start the server.
# pg_ctl -D citus-sr/coordinator2 -l coordinator_logfile start
5. Creating table
Create a table and define the distributed table of the created table on the coordinator1.
# psql
psql (9.6.3)
Type "help" for help.
postgres=# CREATE TABLE sample (id int primary key, data int);
CREATE TABLE
postgres=# SELECT create_distributed_table('sample', 'id');
create_distributed_table
--------------------------
(1 row)
postgres=# INSERT INTO sample SELECT GENERATE_SERIES(1, 10000), GENERATE_SERIES(1, 10000);
INSERT 0 10000
6. Operating data
If you access to the coordinator1, you can obviously do everything what citus can do.
If you access to the coordinator2, you can execute SELECT commands.
# psql -p 5433
psql (9.6.3)
Type "help" for help.
postgres=# SELECT * FROM sample WHERE id < 8 ORDER BY id;
id | data
----+------
1 | 1
2 | 2
3 | 3
4 | 4
5 | 5
6 | 6
7 | 7
(7 rows)
Interestingly,
you can execute DELETE and UPDATE commands using the master_modify_multiple_shards function
even if you access to the coordinator2.
postgres=# SELECT master_modify_multiple_shards('UPDATE sample SET data = data*2 WHERE id < 4');
master_modify_multiple_shards
-------------------------------
3
(1 row)
postgres=# SELECT * FROM sample WHERE id < 8 ORDER BY id;
id | data
----+------
1 | 2
2 | 4
3 | 6
4 | 4
5 | 5
6 | 6
7 | 7
(7 rows)
However, the master_modify_multiple_shards function is not efficient
because it executes UPDATE/DELETE commands for all shards of the target table.